The Trust Boundary Problem: Why Most Enterprise AI Agents Are Architecturally Broken

Most enterprise AI agents I review have the same invisible flaw.
Not in the code. Not in the model. In the architecture.
They are built as if the agent is the centre of the system — the brain that everything else feeds into. The data flows in, the model reasons, the answer flows out. Clean. Simple. Broken.
Here is why.
The Assumption That Breaks Everything
When architects design a Foundry agent or a Copilot Studio bot, they make an implicit assumption: the agent can be trusted to make good decisions because it was given good instructions.
A well-written system prompt. A curated knowledge base. A tested set of topics. Approved connectors.
The assumption is that if you control the inputs you trust, the agent will behave correctly.
This is the wrong mental model. And it fails in production in predictable ways.
What a Trust Boundary Actually Is
In traditional software architecture, a trust boundary is the line between systems or components that operate under different security and reliability assumptions. Data crossing a trust boundary must be validated. Instructions crossing a trust boundary must be verified. Access crossing a trust boundary must be explicitly granted—never assumed.
We apply this rigorously to APIs, microservices, and network zones.
We almost never apply it to AI agents.
An enterprise Foundry agent typically crosses four trust boundaries on every single request:
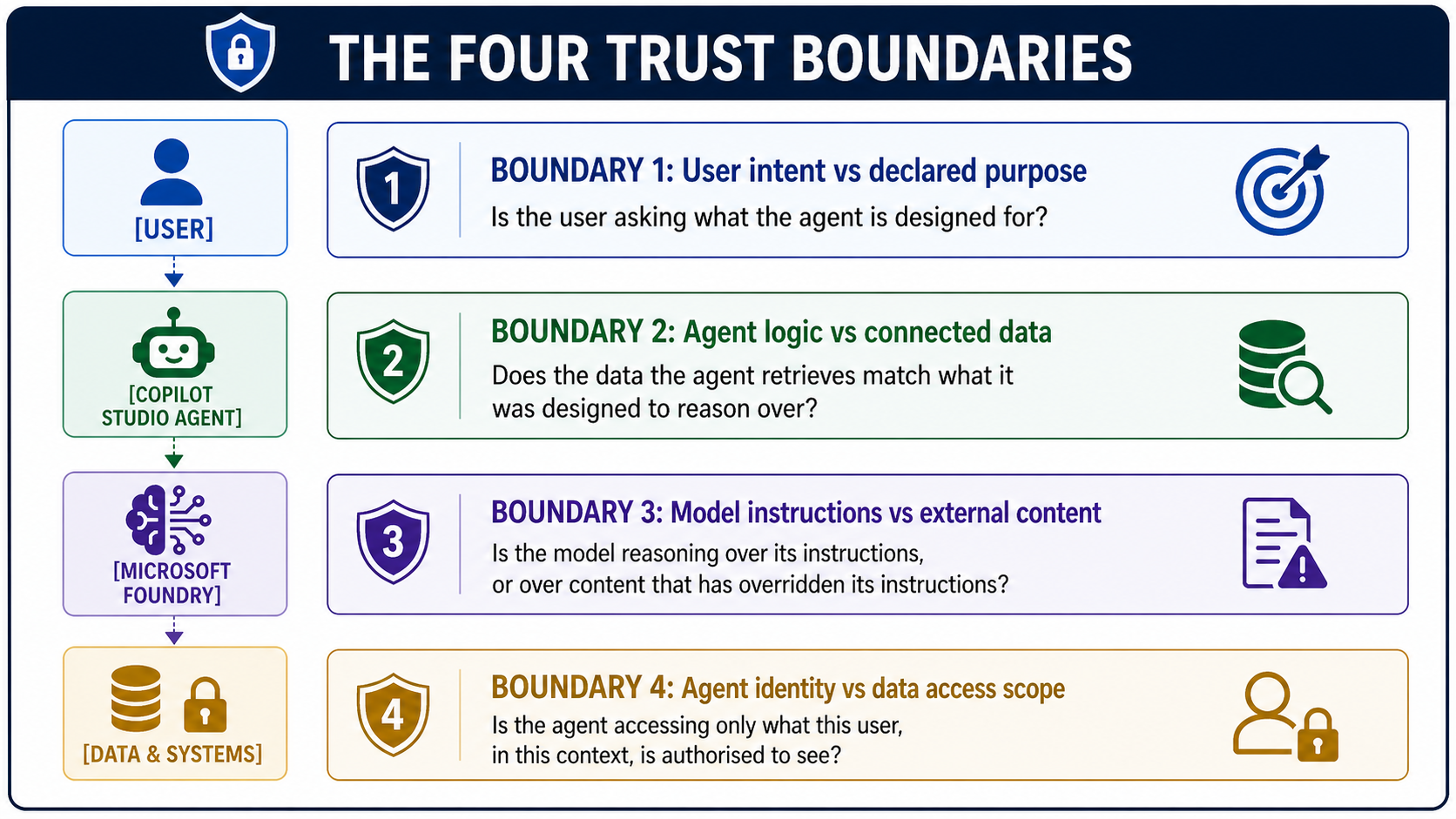
Most enterprise agent architectures explicitly govern zero of these four boundaries. Some govern one. Almost none govern all four.
Why This Matters More Than Prompt Engineering
The industry has spent enormous energy on prompt engineering—making agents smarter, more accurate, and better at following instructions. This is valuable. But it addresses none of the trust boundary problems.
A perfectly prompt-engineered agent that crosses unvalidated trust boundaries is still exploitable. It will still return data the user shouldn't see. It will still follow instructions embedded in a document it was told to summarize. It will still conflate its own reasoning with content injected from outside its control.
Prompt engineering makes agents more capable within a boundary. It does not define, enforce, or protect the boundary itself.
This is the architectural gap.
The Mental Model Shift
The correct way to think about an enterprise AI agent is not as a smart assistant that you make smarter with better prompts.
It is as a process with a defined trust perimeter—where every input is classified by its trust level before the model sees it, every output is validated before the user sees it, and every data access is scoped to the authenticated principal making the request.
This is not a new idea. It is exactly how we design secure APIs, zero-trust networks, and financial transaction systems.
We just forgot to apply it to AI.
The three questions every enterprise architect should ask before any Foundry agent goes to production:
1. What is this agent's declared purpose—and can it be held to it regardless of what it receives as input? Not "Will it usually stay on topic?. "Will it always stay on topic even when a user, a document, or a retrieved search result actively tries to push it off topic?
2. Is the data this agent retrieves scoped to the identity of the requesting user—or does it have ambient access that any query can exploit? An agent with a Reader role on an entire SharePoint site is not a scoped agent. It is a search engine with a conversational interface and no access controls.
3. Is the agent's output validated against what it is permitted to return—or is the model's judgment the last line of defense? The model's judgement is not a security control. It is a capability. These are not the same thing.
The Implication for Microsoft Foundry + Copilot Studio
Microsoft Foundry gives you the tools to enforce all four trust boundaries—Prompt Shield, managed identity, row-level security via Azure AI Search filters, and output content safety. Copilot Studio gives you the orchestration layer to implement user context propagation across every agent call.
The tools exist. The architecture patterns exist.
What is missing, in most enterprise deployments, is the deliberate decision to treat the agent as a trust boundary problem rather than a capability problem.
When you make that shift — when you stop asking "how do I make this agent smarter" and start asking "how do I make this agent's trust boundaries explicit and enforced" — the architecture changes completely. And it becomes significantly harder to break.
The One Thing to Take Away
Every AI agent in your enterprise is either operating within explicit, enforced trust boundaries—or it is operating on hope.
Hope that users won't probe it. Hope that retrieved documents won't contain malicious instructions. Hope that the model will correctly decide what data it should and shouldn't return.
Hope is not an architecture.
Define the boundaries. Enforce them at every layer. Treat the model as a powerful but ultimately untrusted component within a system that does not depend on its good judgement for security.
That is what production-grade enterprise AI architecture actually looks like.