DESIGNING AN IAAS ARCHITECTURE THAT IS RESILIENT – A CASE STUDY

Recently I was hired by a famous restaurant chain which has more than 35 outlets in my state alone and more than 320 nationwide. Initially their ordering process was done mainly via phone and it expanded maximum to emails. Now the ordering system is moved in Azure on IaaS SQL Server instances. They have moved to an internet-based ordering system with IIS Web Servers in Azure with their front-end application for the process of ordering, invoicing and support like complains and feedback options.
However, the customers of the client complained at times of intermittent problems and persistent errors with the website. The client owned a legacy application that had its data tightly coupled to their ordering system and that application couldn’t be changed. Due to these stability issues with their ordering system, the client was prompted to perform a business impact analysis of their application. This resulted in an executive mandate to restore from an issue within maximum four hours and recover to within the last eight hours. There were also complains about the connectivity issues between their branch outlets, main outlets and the corporate office, issues that occurred intermittently. Upon scrutiny, it was discovered that their disk storage had a heightened level of attention due to a critical server running out of disk space. The same issue highlighted a gap in proactive monitoring.
I suggested the marketing department to move their server workloads into Azure by rebuilding each application and they started building their servers utilizing a single Azure storage account. With around 20-25 VMs already, they anticipate their growth. The HR department wanted IT to move workloads to Azure as well and that process was initiated too. Their existing policy was to create a new storage account for each VM. Their Active Directory Configuration had a single domain controller deployed in one location and the connectivity was enabled with a site-to-site VPN gateway.

Their configuration for ordering application was as follows. The web servers were deployed into an availability set with SQL Server at the backend.
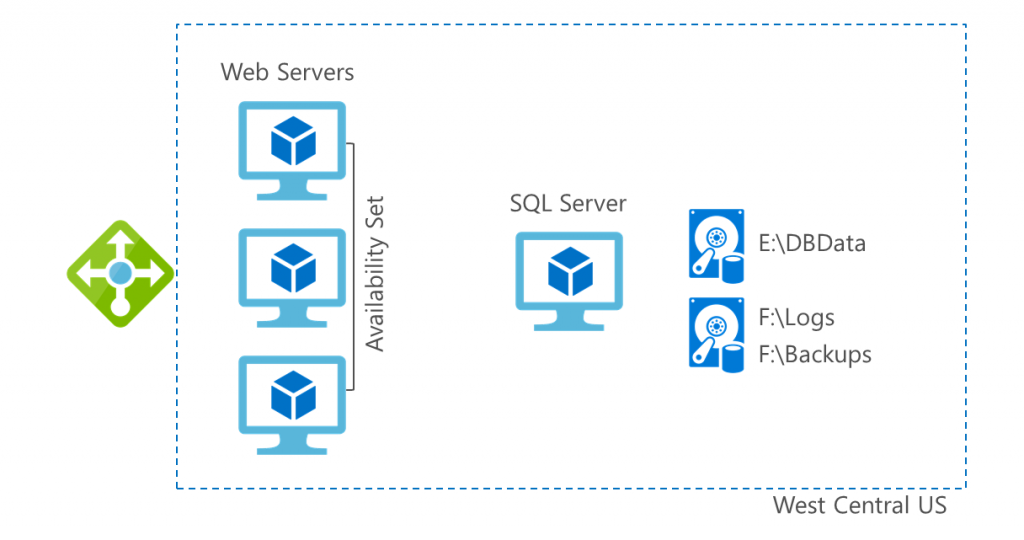
Their IT department was using an outdated guidance on Azure and they needed an updated guidance on their current architectural as well as deployment best practices. They needed assistance with enabling connectivity and authentication for their new infrastructure that is going to deployed soon for their new office. They wanted to identify the infrastructure that had to be configured to provide redundancy and resiliency to the web servers and database servers for their ordering application in order to protect them from system downtime.
In an event of disaster, the client needed an automated mechanism for a quick recovery of their ordering application. They wanted to create a plan for recovery from data corruption or accidental deletion for all their other infrastructure. They also wanted a functional storage policy in place for the anticipation of their growth in Azure along with a monitoring option to foresee issues that may arise on servers an in Azure.
However, the client had some objections in mind. Cost was a huge concern for them because of their increasing infrastructure and server replacement costs. Downtime was an issue for them due to development and production environments not being separate. They wanted to separate those form one another to avoid the issue. Connectivity was also becoming an issue for self-hosting their application’s ordering system, their support website and so on. They were concerned that the cloud may be constrained as well. They were also concerned about the disk space issue that had occurred earlier with their ADDS DCs. They wanted to make sure that the issue would be addressed as per the resiliency plan.
The solution for my client involved several technologies including site-to-site VPN gateway for connectivity from on-premises corporate home office and the branch outlet locations in Azure VNets. Resiliency integrated into each aspect of the deployment and architecture to provide opportunity for high SLA and performance which included the use of managed disks, legacy application being deployed to Azure in a VM with premium storage backed up with Azure Backup, backup vaults in each of the Azure region to provide backups for servers, redundant domain controllers, replication of web tier to secondary region with Site Recovery, SQL Always On Availability Groups with SQL Managed Backup to Azure Storage and orchestration for recovery using Site Recovery’s recovery plans.
Network Security Groups were used to help secure the configuration by limiting traffic flow exactly as a firewall does. As you must know, NSGs may be applied to either individual Network Interface Cards or to Subnets. In this case, there was a single NSG applied to each individual subnet.
For Active Directory, Azur Backup was used to protect the VMs and the storage was configured for resiliency. Domain Controllers were deployed into availability sets in Primary region and all the DCs were made active for DR strategy. For their Order Application, TCB probe was replaced with HTTP and replication was done to a second region with ASR to protect against regional outrages.
Following is an example of the preferred storage approach that was used.

Their existing legacy application could not be moved into an availability set as it was based on only on VM. So, the best solution to that was to run it with Premium Storage which would result in a 99.9% SLA. As the existing hardware on which it was currently deployed on site was aging, moving the application benefited from reduced hardware expenditure through a refresh. Also, the application would eventually require a re-write to take advantage of the advanced features available in Azure. This step would be done once the application is in Azure.
Lastly, I also made the client aware of the key subscription limits that they may encounter and asked to always keep an eye on the documentation for the limits because they change often.